1.🎯 分页概述 #
Model Context Protocol (MCP) 支持对可能返回大型结果集的列表操作进行分页处理。通过分页机制,服务器可以分批返回结果,而非一次性输出所有数据。
分页功能在通过互联网连接外部服务时尤为重要,同时对于本地集成处理大数据集以避免性能问题也非常有用。
2.🔄 分页模型 #
MCP 中的分页采用不透明的基于游标的方法,而非编号页码。
2.1 核心概念 #
- 游标 (Cursor) - 这是一个不透明的字符串Access Token,表示结果集中的位置
- 页面大小 - 由服务器决定,客户端不得假设一个固定的页面大小
2.2 为什么使用游标而不是页码? #
- 更好的性能 - 避免跳页时的性能问题
- 数据一致性 - 防止在分页过程中数据变化导致的问题
- 灵活性 - 服务器可以动态调整页面大小
3.📤 响应格式 #
分页功能在服务器发送数据时开始启用。响应包括:
- 当前结果页面
- 可选的
nextCursor字段(如果存在更多结果则显示)
响应示例:
{
"jsonrpc": "2.0",
"id": "123",
"result": {
"resources": [...],
"nextCursor": "eyJwYWdlIjogM30="
}
}4.📥 请求格式 #
在接收到游标后,客户端可以继续通过包含该游标发起请求来实现分页:
请求示例:
{
"jsonrpc": "2.0",
"method": "resources/list",
"params": {
"cursor": "eyJwYWdlIjogMn0="
}
}5.🔄 分页流程 #
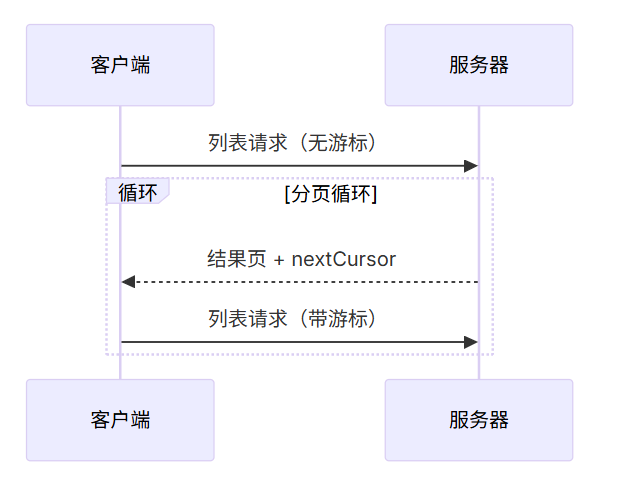
6. 支持分页的操作 #
以下MCP操作支持分页功能:
| 操作 | 描述 |
|---|---|
resources/list |
列出可用资源 |
resources/templates/list |
列出资源模板 |
prompts/list |
列出可用的提示 |
tools/list |
列出可用工具 |
7.🛠️ 实施指南 #
7.1 服务器应该: #
- 提供稳定的游标 - 确保游标在会话期间保持有效
- 优雅处理无效游标 - 返回适当的错误信息而不是崩溃
7.2 客户端应该: #
- 将缺失的
nextCursor作为结果结束 - 当没有nextCursor时停止分页 - 支持分页和非分页两种流程 - 兼容不支持分页的服务器
7.3 客户端必须: #
将游标视为不透明Access Token:
- 不要对光标格式做出假设
- 不要尝试解析或修改游标
- 不要跨会话持久化游标
8.⚠️ 错误处理 #
无效游标应该导致错误代码 -32602(无效参数)。
错误响应示例:
{
"jsonrpc": "2.0",
"id": "123",
"error": {
"code": -32602,
"message": "Invalid cursor"
}
}9. 最佳实践 #
9.1 服务器端实现示例 #
# 导入base64模块用于编码和解码游标
import base64
# 导入json模块用于序列化和反序列化数据
import json
# 从typing模块导入类型注解
from typing import List, Dict, Any, Optional
# 定义MCPServer类
class MCPServer:
# 构造函数,初始化分页大小和游标缓存
def __init__(self):
# 设置每页资源数量为50
self.page_size = 50
# 初始化游标缓存字典
self.cursor_cache = {}
# 列出资源,支持分页,cursor为可选参数
def list_resources(self, cursor: Optional[str] = None) -> Dict[str, Any]:
"""列出资源,支持分页"""
try:
# 如果提供了游标,则解码游标获取偏移量
if cursor:
cursor_data = self._decode_cursor(cursor)
offset = cursor_data.get('offset', 0)
# 如果没有游标,则从头开始
else:
offset = 0
# 获取指定偏移量和页面大小的数据
resources = self._get_resources(offset, self.page_size)
# 构建响应字典,包含当前页的资源
result = {
"resources": resources
}
# 如果返回的资源数量等于页面大小,说明可能还有更多数据
if len(resources) == self.page_size:
# 生成下一个游标,偏移量加上页面大小
next_cursor = self._encode_cursor({
'offset': offset + self.page_size
})
# 在结果中加入nextCursor字段
result["nextCursor"] = next_cursor
# 返回结果
return result
# 捕获异常,抛出无效游标的错误
except Exception as e:
raise ValueError(f"Invalid cursor: {e}")
# 编码游标,将数据字典转为base64字符串
def _encode_cursor(self, data: Dict[str, Any]) -> str:
"""编码游标"""
# 将数据字典序列化为JSON字符串
json_str = json.dumps(data)
# 编码为base64字符串并返回
return base64.b64encode(json_str.encode()).decode()
# 解码游标,将base64字符串还原为数据字典
def _decode_cursor(self, cursor: str) -> Dict[str, Any]:
"""解码游标"""
try:
# 解码base64字符串为JSON字符串
json_str = base64.b64decode(cursor.encode()).decode()
# 反序列化为字典并返回
return json.loads(json_str)
# 捕获异常,抛出无效游标格式的错误
except Exception:
raise ValueError("Invalid cursor format")
# 获取资源数据(模拟实现)
def _get_resources(self, offset: int, limit: int) -> List[Dict[str, Any]]:
"""获取资源数据(模拟)"""
# 实际应用中应替换为数据库查询
return [
{"uri": f"file:///resource_{i}", "name": f"Resource {i}"}
for i in range(offset, offset + limit)
]9.2 客户端实现示例 #
// 定义MCPClient类,用于与服务器进行资源分页交互
class MCPClient {
// 构造函数,初始化基础URL和连接对象
constructor() {
// 服务器基础WebSocket地址
this.baseUrl = 'ws://localhost:8080';
// 连接对象,初始为null
this.connection = null;
}
// 异步方法:获取资源列表,支持游标分页
async listResources(cursor = null) {
// 构造JSON-RPC请求对象
const request = {
jsonrpc: "2.0",
id: this.generateId(),
method: "resources/list",
// 如果有游标则带上,否则为空对象
params: cursor ? { cursor } : {}
};
try {
// 发送请求并等待响应
const response = await this.sendRequest(request);
// 返回响应中的result字段
return response.result;
} catch (error) {
// 捕获异常并输出错误信息
console.error('Failed to list resources:', error);
// 继续抛出异常
throw error;
}
}
// 异步方法:获取所有资源,自动处理分页
async getAllResources() {
// 用于存储所有资源的数组
const allResources = [];
// 初始游标为null
let cursor = null;
// 循环获取每一页资源,直到没有更多游标
do {
// 获取当前页资源
const result = await this.listResources(cursor);
// 合并当前页资源到总数组
allResources.push(...result.resources);
// 更新游标为下一页
cursor = result.nextCursor;
} while (cursor);
// 返回所有资源
return allResources;
}
// 异步方法:分页获取资源,并在每页结束时回调进度
async listResourcesWithProgress(callback) {
// 用于存储所有资源的数组
const allResources = [];
// 初始游标为null
let cursor = null;
// 页数计数器
let pageCount = 0;
// 循环获取每一页资源
do {
// 页数加一
pageCount++;
// 获取当前页资源
const result = await this.listResources(cursor);
// 合并当前页资源到总数组
allResources.push(...result.resources);
// 更新游标为下一页
cursor = result.nextCursor;
// 如果有回调函数,则调用,传递当前进度信息
if (callback) {
callback({
page: pageCount, // 当前页码
totalItems: allResources.length, // 累计资源数
hasMore: !!cursor // 是否还有下一页
});
}
} while (cursor);
// 返回所有资源
return allResources;
}
// 生成唯一请求ID的方法
generateId() {
// 生成一个9位的随机字符串
return Math.random().toString(36).substr(2, 9);
}
// 异步方法:发送请求到服务器(模拟实现)
async sendRequest(request) {
// 返回一个Promise,模拟网络请求
return new Promise((resolve, reject) => {
// 这里应为真实的WebSocket或HTTP请求
setTimeout(() => {
// 模拟服务器响应
resolve({
jsonrpc: "2.0",
id: request.id,
result: {
resources: [],
nextCursor: null
}
});
}, 100); // 模拟100ms延迟
});
}
}
// 使用示例
// 创建MCPClient实例
const client = new MCPClient();
// 获取所有资源,并在获取完成后输出资源数量
client.getAllResources().then(resources => {
console.log(`获取到 ${resources.length} 个资源`);
});
// 分页获取资源,并在每页结束时输出进度
client.listResourcesWithProgress((progress) => {
console.log(`第 ${progress.page} 页,共 ${progress.totalItems} 个项目`);
if (!progress.hasMore) {
console.log('分页完成!');
}
});10.🔍 分页策略 #
10.1 基于偏移量的分页 #
# 定义一个简单但有效的分页策略函数
def get_paginated_data(offset: int, limit: int):
# 调用 fetch_data 函数获取从 offset 开始、数量为 limit 的数据
# 返回一个字典,包含数据和下一个游标
return {
# "data" 字段存放当前页的数据
"data": fetch_data(offset, limit),
# 如果还有更多数据,则生成下一个游标,否则为 None
"nextCursor": encode_cursor({"offset": offset + limit}) if has_more else None
}10.2 基于时间戳的分页 #
# 定义一个基于时间戳游标的分页函数,适用于时间序列数据
def get_paginated_data_by_time(cursor: Optional[str] = None):
# 如果提供了游标,则解码游标并获取上次的时间戳
if cursor:
last_timestamp = decode_cursor(cursor)["timestamp"]
# 如果没有游标,则从头开始(last_timestamp为None)
else:
last_timestamp = None
# 获取自上次时间戳以来的最新数据,最多返回50条
data = fetch_data_since(last_timestamp, limit=50)
# 返回当前页数据和下一个游标(如果有数据则生成,否则为None)
return {
"data": data,
"nextCursor": encode_cursor({"timestamp": data[-1]["timestamp"]}) if data else None
}11.📊 性能考虑 #
11.1 服务器端优化 #
- 索引优化 - 确保查询字段有适当的索引
- 游标缓存 - 缓存常用的游标状态
- 批量查询 - 使用批量操作减少数据库往返
11.2 客户端优化 #
- 并发控制 - 限制同时进行的分页请求数量
- 缓存策略 - 缓存已获取的数据避免重复请求
- 错误重试 - 实现指数退避的重试机制
12.🎯 总结 #
MCP的分页功能为处理大型数据集提供了高效、灵活的解决方案。通过使用不透明的游标机制,既保证了性能又确保了数据一致性。
12.1 关键要点: #
- 🔄 使用游标而非页码 - 更好的性能和一致性
- 📤 响应包含 nextCursor - 指示是否有更多数据
- 🛡️ 游标是不透明的 - 不要解析或修改游标
- ⚠️ 优雅处理错误 - 无效游标返回 -32602 错误
- 支持多种操作 - resources、prompts、tools 等
12.2 最佳实践: #
- 🎯 选择合适的页面大小 - 平衡性能和用户体验
- 🔄 实现进度反馈 - 让用户了解分页进度
- 🛡️ 错误处理 - 优雅处理网络错误和无效游标
- 📊 性能监控 - 监控分页操作的性能指标